
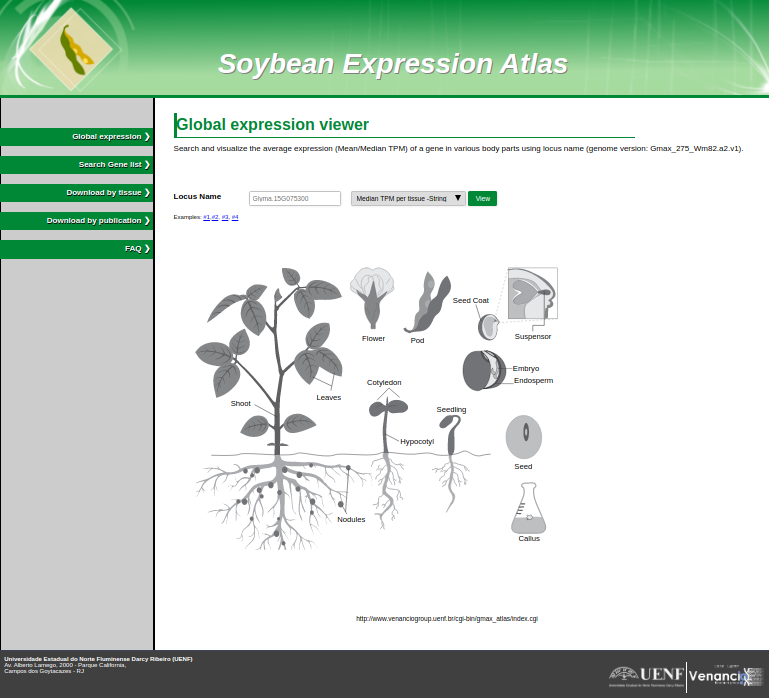
Soybean (Glycine max [L.] Merr.) is a major crop in animal feed and human nutrition, mainly for its rich protein and oil contents. The remarkable rise in soybean transcriptome studies over the past five years generated an enormous amount of RNA‐seq data, encompassing various tissues, developmental conditions, and genotypes. In this study, we have collected data from 1,298 publicly available soybean transcriptome samples, processed the raw sequencing reads, and mapped them to the soybean reference genome in a systematic fashion. We found that 94% of the annotated genes (52,737/56,044) had detectable expression in at least one sample. Unsupervised clustering revealed three major groups, comprising samples from aerial, underground, and seed/seed‐related parts. We found 452 genes with uniform and constant expression levels, supporting their roles as housekeeping genes. On the other hand, 1,349 genes showed heavily biased expression patterns towards particular tissues. A transcript‐level analysis revealed that 95% (70,963/74,490) of the assembled transcripts have intron chains exactly matching those from known transcripts, whereas 3,256 assembled transcripts represent potentially novel splicing isoforms. The dataset compiled here constitute a new resource for the community, which can be downloaded or accessed through a user‐friendly web interface at venanciogroup.uenf.br/resources . This comprehensive transcriptome atlas will likely accelerate research on soybean genetics and genomics.
Link of publication HERE
Publications 15
Research 2
 Posted on 08 Dec 2021
Posted on 03 Nov 2021
Posted on 08 Dec 2021
Posted on 03 Nov 2021
New paper published! - Phylogenetic analysis and population structure of Pseudomonas alloputida
Posted on 03 Nov 2021
Posted on 03 Nov 2021
